if(kakao) dev 2019(카카오 개발자 컨퍼런스) 내용 중 README.ocr 발표 내용 정리
친구가 정말 좋은 정보를 알려주어서 자세히 보게 되었다! (멋진 녀석!)
직접 참여하진 못했지만, 모든 발표 자료들이 open(!) 되어있다. 카카오 사랑해요!
> https://if.kakao.com/2019/program
if kakao 개발자 컨퍼런스 2019
세상은 전부 개발거리, if kakao 2019 - if.kakao.com
if.kakao.com
읽어보고 도움이 많이 된 OCR 발표 자료를 개인적으로 요약 정리하려고 한다. 발표해주신 박선규님 감사합니다!
(※ if(kakao) dev 2019의 아래 발표 자료와 영상에서 인용하였음을 밝힙니다.)
[Day2, R5, 12:00-12:45] README.ocr : 딥러닝 기반 문자인식 프로젝트, 박선규님(louis.park)
소개 : https://if.kakao.com/2019/program?sessionId=3a33fb73-aee2-4a39-b731-1fa5564f2b82
≪ Introduction ≫
# OCR이 뭐죠?
- Optical Character Recognition, 이미지에서 글자를 읽어주는 알고리즘
- 카카오 OCR 모델의 구조 (Scene Text Detection)
1) Detector : 주어진 이미지의 어느 위치에 글자들이 있는지 찾아줍니다. (Image Crop)
2) Recognizer : Detector가 찾은 위치에 어떤 글자가 쓰여 있는지 읽어줍니다. (Image to Text)


# OCR이 어려운 이유?
- Large Number of Classes : 글자의 수많은 기호를 서로 분류해야 한다.
(ex) 중국어/일본어 : 한자 인식, 한글 : 자·모음 조합으로 총 2500개 이상의 기호 분류
- Intraclass Variance : 같은 글자도 이미지에서는 얼마든지 다른 모양, 크기로 등장 가능
≪ OCR 데이터 모으기 ≫
# 오픈소스 OCR 데이터셋 활용
- ICDAR 2019 Robust Reading competitions datasets
- 장점 : 많은 양의 데이터를 손쉽게 Get
- 단점 : 정확하지 않은 라벨 포함된 경우가 많고, 원하는 언어 데이터를 구할 수 없다.
# 이미지 수집과 라벨링

- 웹 크롤링 등으로 사진을 모으고 직접 라벨링
- 장점 : 양질의 데이터 Get, 애매한 경우의 annotation을 조절 가능 (일관성 있게 처리하는 것 중요)
- 단점 : 비용 문제
# 합성 데이터 1 : SynthText ( http://www.robots.ox.ac.uk/~vgg/data/scenetext/ )

- 장점 : 배경 이미지와 폰트, 텍스트를 원하는 대로 가공 가능
- 단점 : 비싼 라벨(Segmentation mask, Camera depth map) 필요, 비사실적 데이터 생성
# 합성 데이터 2 : 자체 개발 데이터 합성 툴
- 오픈된 서체로 배경+글자 이미지 생성
- 장점 : 배경 이미지와 폰트 & 텍스트를 원하는 대로 가공 가능, 대량의 데이터 생성 가능
- 단점 : 결과 이미지를 보면서 튜닝, Recognizer용으로만 사용 가능
≪ 글자 영역 검출 (Scene Text Detection) ≫
# Regression-based Methods
- Rotation-awareness in text bounding boxes
- 일반 Object Detection 모델들과는 달리 OCR에서는 텍스트의 회전 고려가 필수
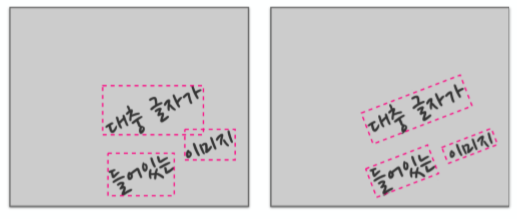
- EAST: An Efficient and Accurate Scene Text Detector (CVPR2017)

- EAST paper : https://arxiv.org/abs/1704.03155
- 장점 : (당시) 일정 수준 이상의 성능을 가진 모델들 중 가장 빠른 속도
- 단점 : 글자 크기에 취약, 불규칙 배열 글자 검출 불가능, 복잡한 후처리(non-maximum suppression 등)
# Segmentation-based Methods
- Using weakly annotated labels
- 픽셀 단위 라벨링(좌측)은 어렵고 비효율적이므로, Bounding-box를 변형(우측)해서 사용하는 경우가 많다.
- Weak supervision이 주어진 상황에서 Instance Segmentation 문제를 푸는 것

- DeepLab V3+ (현재 kakao에서 변형하여 사용 중인 모델)

- DeepLab V3+ papar : https://arxiv.org/abs/1802.02611
- SPP(Spatial Pyramid Pooling)에서 다양한 커널 사이즈를 이용하기 때문에 크기 변화에 강함 예상
- 장점 : 성능 향상(pixel-wise loss 기준 2%, 글자 크기 변화에 강함), 후처리 과정 간소화,
단어 끝 글자 잘리는 현상 감소
- 단점 : 작은 글자 여러 줄이 가까이 있으면 한 줄로 인식하는 현상
# Regression-based & Segmentation-based Result Comparison

# Segmentation-based methods : 극복 방법 예시
- PixelLink (AAAI 2018)
- paper : https://arxiv.org/abs/1801.01315
- 각 픽셀마다 주변 8개 픽셀이 같은 단어에 속하는지를 예측

≪ 글자 인식 (Scene Text Recognition) ≫
# Improvements on Recognizer

- Synthetic data(한글 15600k + 영문 800k) = 16400k
- Real data(한글 20.7k + 영문 22k) * 10배 Augmentation = 427k
- 전체 데이터의 약 2%를 실제 데이터로 사용
- 배치 내에서 Synthetic : Real = 10 : 1의 weighted sampling
- Train with Real data : word-level accuracy 85.98, character error rate 5.93까지 성능 개선
# 불규칙한 배열의 글자 인식
- ICDAR19 RRC on Arbitrary-Shaped Text Dataset
- 곡선 형태 등 불규칙하게 배열된 글자들에 대한 인식 문제
- ASTER : An Attentional Scene Text Recognizer with Flexible Rectification (TPAMI2018)
- Flattening irregular images with STN(Spatial Transformer Network)
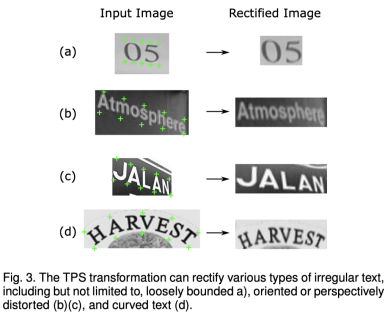
- 이미지 변환에 쓰일 control points를 찾아내어, 네트워크가 처리하기 좋게 Rectify 해주는 모듈
- Text Recognizer 전에 STN을 적용하여 irregular text의 성능을 높이는 시도
- ASTER와 비슷한 적용 가능성 제시

- 별도의 모듈 추가 없이, Detector의 Segmentation 결과에서 mask를 이용하여 변형 적용
- 글자 방향 인식

- 세로 쓰기 또는 다른 방향으로 돌아가 있는 글자가 있으면 모델의 성능이 크게 떨어질 수 있다.
- Recognizer에서 별도의 classifier 또는 모듈을 이용해 돌려야 하는 방향을 판단하려는 시도
≪ Conclusion ≫
# Current performance of API




# On-device Demonstration
- OCR running on mobile device with Tensorflow-lite

- TF-lite를 이용해 모바일에서 동작하도록 OCR 모델 테스트
(Q&A에서 MobileNet v3 사용하셨다고 언급하심)
- 실시간 처리나 민감한 개인 정보 등의 경우에서 사용 가능할 것으로 보임
- 속도는 빠르지만, 인식 성능 크게 저하
우와.... OCR 관련 지식을 쌓는 데에 아주 많은 도움이 되었다!
개인적으로 정리를 하면서 논문이나 용어들, 방법론이나 트렌드 등의 정보를 상당 부분 이해한 것 같다.
내년에 if(kakao) dev 2020이 열린다면, 꼭 참여하고 싶은 생각이 든다.
다시 한번 카카오와 박선규님께 감사, 이 정보를 알려준 친구에게 감사, 하나님께 감사하다.
'Deep Learning' 카테고리의 다른 글
| 데이터 사이언스 스쿨 - 딥러닝 (0) | 2019.11.12 |
|---|---|
| Kaggle - Denoising Dirty Documents (0) | 2019.10.15 |
| GAN(Generative Adversarial Nets)을 파악해보자! (0) | 2019.10.15 |
| 딥러닝 전문가와의 대화 (0) | 2019.10.15 |
| Kaggle 입문기 (0) | 2019.10.15 |


댓글